I would like to take an opportunity to write up a post that introduces the concepts of sensitivity and specificity as they are used in the context of medical tests. I’d like to explain how these values affect our understanding of the disease state of a person or animal based on the result of a test.
Medical tests are not 100% accurate. Therefore, there are some patients that do not have a disease state that will test positive and some patients that do have a disease state that will test negative. The way that we quantify the accuracy of a test is using two concepts - sensitivity and specificity.
In the following discussion I am going to use the symbols \(+\) to indicate a positive test result, \(-\) to indicate a negative test result, \(\text{D}\) to indicate the patient has the condition/disease and \(\neg \text{D}\) to indicate the patient does not have the condition/disease.
Terminology
Sensitivity is the measure of how often the test is positive for patients that have the condition that is being tested. In probability language it is the conditional probability of a postive test given the patient has the condition/disease. Symbolically this is \(\text{P}(+ \vert \text{D})\).
Specificity is the measure of how often the test is negative for patients that do not have the condition. Probabilistically we say that it is the probability of a negative test given the patient does not have the condition/disease. In symbols this is \(\text{P}(- \vert \neg \text{D})\).
There are a couple of other terms that I would like to introduce. The first is positive predictive value (PPV). This is the probability of having a condition/disease given a positive test result. Symbolically, \(\text{P}(\text{D} \vert +)\). The other is negative predictive value (NPV). You can probably guess that this is the probability of not having a condition/disease given a negative test result. Symbolically this is represented as \(\text{P}(\neg \text{D} \vert -)\). We will use these below to answer the questions that we really care about when we are looking at test results for a patient.
One final term to cover then I can get into the meat of the matter. disease prevalence is the proportion of the population at risk for a condition or disease that has the condition/disease. Symbolically this can be written, \(\text{P}(\text{D})\) (the probability of having the condition/disease).
Why are sensitivity and specificity important?
Now that I have covered all that you may be asking, so what? Let’s say that you have had an antibody test for Lyme disease on your dog and the test has come back positive. If I tell you that the sensitivity of the test is 94% and the specificity is 96%, what is the probability that your dog actually has Lyme disease (\(\text{P}(\text{D} \vert +)\))? (these are the actual values from a commonly used Lyme test for dogs). Think about it for a minute before going on.
Did you say something close to 94%? Or did you come up with something much lower? Well, the actual answer is that I didn’t give you enough information to come up with a number. In order to answer that question you also need to know the prevalence of Lyme disease in the population of dogs. Let’s see why this is using some concrete numbers.
An example using concrete numbers
Let’s assume we have a population of 10,000 dogs in our area and the prevalence of Lyme disease is 5%. So we have 500 dogs with Lyme disease and 9,500 without Lyme disease. Now I’m going to count how many dogs test positive and how many test negative. Recall that sensitivity is the percent of patients with the disease that will test positive. So with a sensitivity of 94% we will have \(500 * 0.94 = 470\) dogs with Lyme disease that will test positive. Therefore 30 dogs with Lyme disease will test negative.
I told you above that specificity is the percent of patients that do not have the disease that will test negative. Thus, out of the 9,500 dogs without the disease, \(9500 * 0.96 = 9120\) will test negative. It follows then that 380 dogs without Lyme disease will test positive.
Let’s look at this in tabular form
| \(\text{D}\) | \(\neg \text{D}\) | |
|---|---|---|
| \(+\) | 470 | 380 |
| \(-\) | 30 | 9120 |
Hopefully you can see from this that the proportion of dogs that test positive that actually have the disease is \(\frac{470}{(470+380)}=0.55\). So the probability that your dog has Lyme disease given a positive test with the given test specificity and sensitivity is only 55% (this is what I called positive predictive value above). Can you see how this probability depends on the prevalence of the disease in the population?
Let’s rework this assuming a disease preavalence of 10%. We now have 1,000 dogs with Lyme disease and 9,000 without. Now the table looks like this
| \(\text{D}\) | \(\neg \text{D}\) | |
|---|---|---|
| \(+\) | 940 | 360 |
| \(-\) | 60 | 8640 |
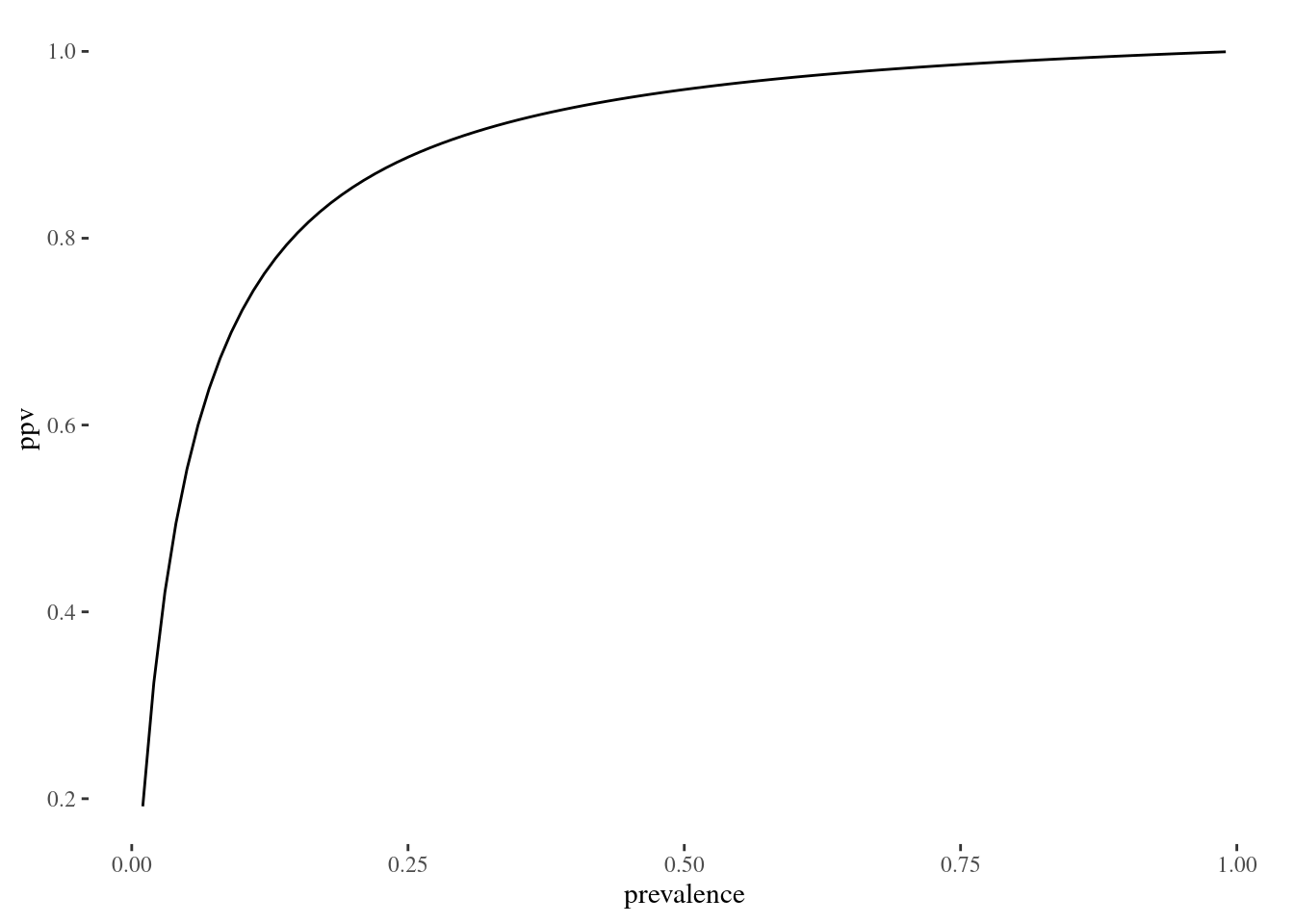
Now the positive predictive value (probability the dog has Lyme given a positive test) is \(\frac{940}{940+360}=0.72\) or 72%. Quite a difference. Let’s look at a graph of PPV by different disease prevalences.
library(ggplot2, warn.conflicts = FALSE, quietly=TRUE)
library(ggthemes, quietly = TRUE)
population = 10000
sensitivity = 0.94
specificity = 0.96
prevalence = seq(0.01, 0.99, 0.01)
diseased = population * prevalence
nondiseased = population - diseased
true_positive = diseased * sensitivity
false_positive = nondiseased - (nondiseased * specificity)
ppv = true_positive / (true_positive + false_positive)
ggplot() + geom_line(aes(x=prevalence, y=ppv)) + theme_tufte()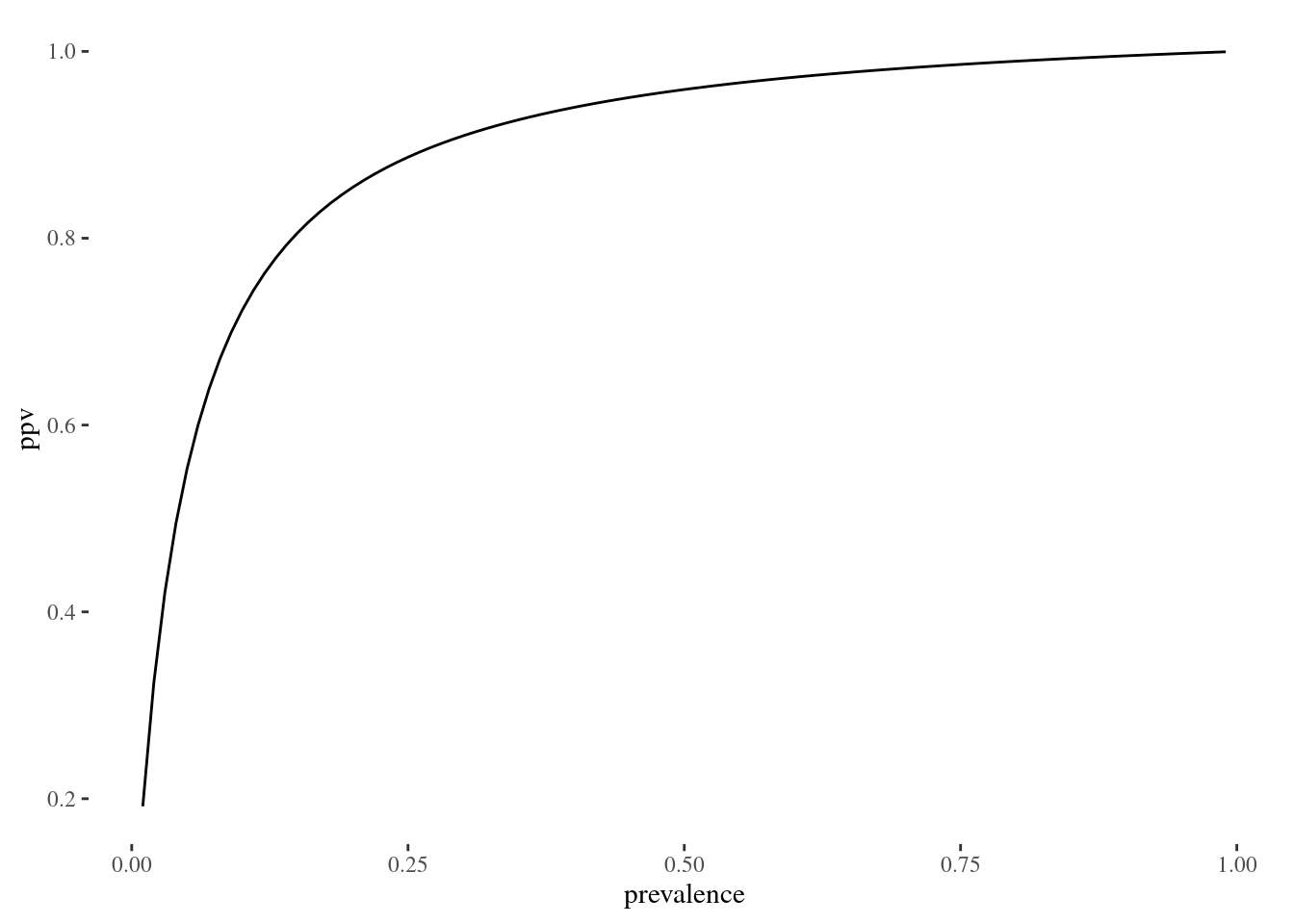
Probability and Bayes rule
If you have studied probabiltity you have probably come across Bayes Rule (also called Bayes Theorem). You probably had some sense in the discussion above that we might be dealing with an application of Bayes Rule here. In fact, many courses use an example very similar to this when they first teach Bayes Rule. Recall that in general terms Bayes Rule is
\[ \text{P}(y|x) = \frac{\text{P}(x|y) \text{P}(y)}{\text{P}(x)} \]
Essentially it gives us a way to calculate the reverse conditional probability. In other words we can calculate the probability of \(y\) given \(x\) if we know the probability of \(x\) given \(y\) (plus those other two terms). Usually \(\text{P}(y|x)\) is called the posterior distribution, \(\text{P}(x|y)\) is called the liklihood of \(x\) given some \(y\), \(\text{P}(x)\) is the prior distribution of of \(x\) (also called the marginal distribution) and \(\text{P}(y)\) is the marginal distribution of \(y\) over all values of \(x\).
Ok, you may be asking what does this have to do with what you were talking about in the beginning of the post? Does it help if I rewrite Bayes Rule using our symbols for positive tests and disease states?
\[ \text{P}(D|+) = \frac{\text{P}(+|D) \text{P}(D)}{\text{P}(+)} \]
Ignoring the term in the denominator for now can you see what the other terms are?
\[ PPV = \frac{\text{sensitivity} \cdot \text{prevalence}}{\text{P}(+)} \]
Now let’s look at the denominator. Well that’s the probability of a positive test. Knowing what we know how can we calculate that? I will derive it in a minute from the product and sum rule of probability, but let’s see if we can understand it intuitively. To get a positive test either you have the disease and the test correctly gave a positive result or you do not have the disease and the test gave you a false positive result. As I showed above the first case is the sensitivity weighted by the prevalence of the disease. The second case is the inverse of the specificity weighted by the proportion of the population without the disease.
Here is the breakdown using probability. We first apply the sum rule and the fact that our \(D\) variable only has two values
\[ \text{P}(+) = \sum_\text{D} \text{P}(+, D) = \text{P}(+, \text{D}) + \text{P}(+, \neg \text{D}) \]
Now I’ll apply the product rule to each of these joint probabilities
\[ \text{P}(+, \text{D}) + \text{P}(+, \neg \text{D}) = \text{P}(+ \vert \text{D}) \text{P}(D) + \text{P}(+ \vert \neg \text{D}) \text{P}(\neg \text{D}) \]
Ok, now we’re getting somewhere. I recognize a couple of those terms and can compute the others from the things that I do know. From left to right \(\text{P}(+ \vert \text{D})\) is the sensitivity, \(\text{P}(D)\) is the prevalence, \(\text{P}(+ \vert \neg \text{D})\) is 1-specificity and \(\text{P}(\neg \text{D})\) is 1-prevalence. So finally we can write down the equation for Bayes Rule that includes only sensitivity, specificity and prevalence as
\[ \text{P}(D|+) = \frac{\text{P}(+|D) \text{P}(D)}{\text{P}(+, \text{D}) + \text{P}(+, \neg \text{D})} = \frac{\text{sensitivity} \cdot \text{prevalence}}{\text{sensitivity} \cdot \text{prevalence} + (1-\text{specificity}) \cdot (1-\text{prevalence})} \]
For good measure let’s plot the PPV given by this equation against the prevalence to compare to what we did above.
sensitivity = 0.94
specificity = 0.96
prevalence = seq(0.01, 0.99, 0.01)
ppv = (sensitivity * prevalence) / ((sensitivity * prevalence) + ((1-specificity) * (1-prevalence)))
ggplot() + geom_line(aes(x=prevalence, y=ppv)) + theme_tufte()